# Weird software: library.joy.pm
Why a simple notion database when you can make it 100 times more complicated but more fun?
Ok, let’s be honest. This is overkill. This is too much. A simple notion page is enough for this but… this is 10 times more fun. Architecturally speaking this is an exercise in gratuitous complexity.
The finished product is in library.joy.pm.
What is library.joy.pm?
I take notes when reading books. But I do it in a very disorganized way. Sometimes I just scribble the pages (when it is a physical book) and some others I take some notes in notion. I also have plenty of markdown files scattered in many places. And don’t forget some emacs org files. I think I have those too.
This is my small attempt to become a bit more organized. I want to automate the boring parts and let me just do the thinking.
Just markdown files
Markdown files are absolutely awesome to keep notes. It is a simple format, it looks relatively future proof and you can version it in git. Indeed this same blog is written mostly using markdown and it works just fine.
So let’s start there. Let’s just create a git repo and put markdown files there.
I could have stopped there. Github renders markdown just fine and notes look great. You have a web interface and plenty of accessibility. It is more than enough for some geeky book notes.
A better visualization
Ok, let’s take another step just for the sake of it. Let’s build a website so I can present all those markdown files in a decent way. I could have used Jekyll or Hugo but I wanted to try something new. I like pandoc a lot. Sombody that keeps a huge Graphviz with 10000 intercrossed lines between file formats in their homepage must be nice people.
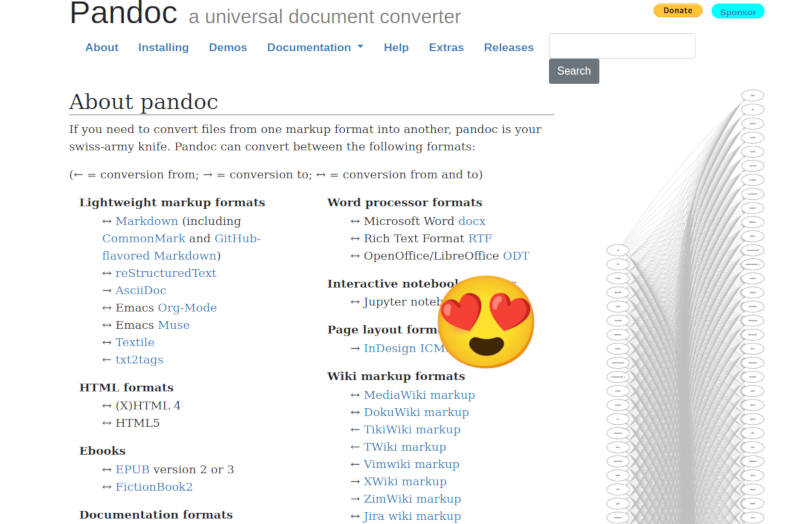
Pandoc is a great tool to convert between formats. We can use it to convert markdown to html.
pandoc -f drive.md -o drive.htmlThat would convert the notes on Markdown to HTML. Simple and neat. Pandoc supports templates too so you can just
pandoc -f drive.md -o drive.html --template layout.htmlAnd that will apply the layout.html template to the output of pandoc. Let’s take a look how how templates look
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link rel="stylesheet" href="/style.css">
<title>$title$</title>
</head>
<body>
<div class="container">
$body$
</div>
</body>
</html>You have some template variables in the template. The body is
$body$ and it will be substituted by the output of the
pandoc. Now we have a beautiful stylesheet so we can see something
decent.
Let’s apply a bit of magic pixie dust in form of a Makefile and we have our first version of a notes website.
This could be enough.
It would be great if we had the cover shown
If you paid close attention to the template I shown before you’ll see
there is a $title$ variable. Pandoc parses YAML front
matter in the markdown files to apply those variables to the template.
So we can:
---
title: Drive
---
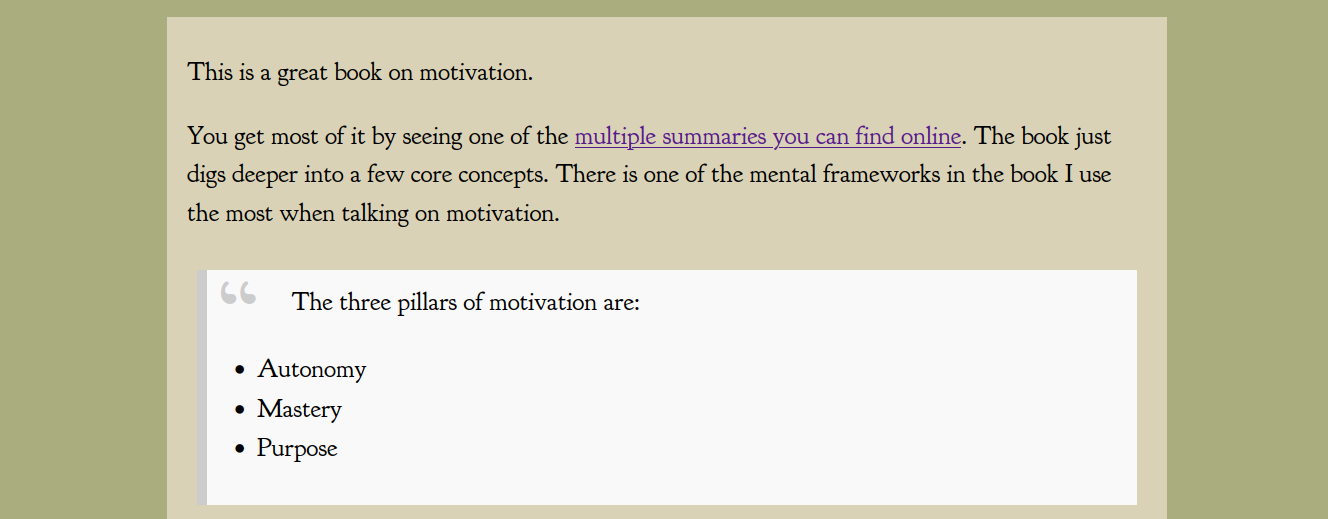
This is a great book on motivation.
[...]And pandoc will substitute the title variable with the value of the title.
Also, I wanted to show the cover of the book. So I could add just some more metadata there and use The Open Library images to be shown there. According to their documentation we can create a link with the following url:
https://covers.openlibrary.org/b/olid/$openlibrary_id$-L.jpgI could then just add
---
title: Drive
openlibrary_id: OL15016965W
---
[...]And in the template use that HTML.

But that is a bit of a pain in the ass. I need to open the browser, look for the book and find the code. That is a bit time consuming for me. Also, that will make me consume bandwidth of the open library so I’d prefer to be a good citizen and host the images myself.
This may be a good opportunity to use a bit of Rust to create a command line tool so I can ask it to generate the template file for me.
The Open Library API is extremely simple and it does not need authentication so I can use it to get the cover and some metadata like the author of the books. I will add those to the templates.
Also, I can use direnv to change the PATH automatically when entering the code folder so I have the latest debug version of the binary easily accessible.
It is just writing post_template adding a bit of Tui-rs to the mix and I am
ready to go!


 0:00
0:00
/0:54
1×


Metadata as your database
Ok, so there we are. We can take notes and create new book pages easily. Anyway I have one last annoyance. I have to manually keep the index page adding every new book there and keeping the order. I could generate the index page automatically but then I can sort the new books by a single criteria. Having a static page is a must for me so I have to check other options. Let’s go overkill again.
I am accepting the metadata in markdown files as a the source of truth but that does not mean it has to be the only one. Since I am using a tool already to download the images and generate templates I can use the same tool to maintain a secondary metadata database.
I can maintain a sqlite database and upload it to the static site. Then I can use a WASM version of sqlite to load that database straight on from the browser and use it to generate the index page.
xhr = new XMLHttpRequest();
xhr.open("GET", "/metadata/books.sqlite", true);
xhr.responseType = "arraybuffer";
xhr.onload = function(e) {
let database_data = new Uint8Array(xhr.response);
const db = new SQL.Database(database_data);
let sqlstr = "SELECT title, slug, finished_at, last_updated_at FROM books;";
const result = db.exec(sqlstr, {});
result[0].values.forEach(addToTable);
};And yes, I could just create the table straight away but this looks absurdly more fun. Also it opens a lot of possibilities in order to display the information in funnier ways in the future.
Then I am using DataTables to display the index so it is still readable as I add books. Also, I get for free the sorting and searching features.
Finishing touches
Just some minor details. For example, this is the first site I use Ackee to gather visit statistics. It is self hosted and cookie-less so metrics are tracked in a privacy sensitive way. Let’s see how it works. I love the fact that I don’t have to set cookies for a web like this but I’d love also to have statistics on the number of visitors. On paper this looks like a reasonable solution.

What now?
I will start migrating more notes there. At this moment I just have a small PoC to check that everything is working properly. I could download the images in parallel, I could have a way to perform a full sync, I can show more info in the pages, I can add tags… This will have to be iterated. But this is the good thing on writing your own software.
Also with use I will discover more bugs in it. For example now I can easily my notes on a book. I have to take a look to that.
Why weird software?
This software could have been a Notion page. And it would have worked just fine. From time to time it is nice to relax and do some overengineering just for fun. And this is what it is. An exercise in having fun with your tools and your workflow. I will try to keep using it because after writing this I am a lot more involved with it than with a boring (but more effective) Notion page.
Also writing this software allows me to take some takeaways:
- TUI in Rust is easier than what I thought
- Embedding SQL in a webpage with no backend is a nice tool when you want to give users a lot of freedom to explore data
- Automate all the things!
- The Open Library is a beautiful project and it has a lot of potential. I ditched GoodReads already.
- I have no eye for design
- I should read more
I had loads of fun writing this. I hope you had fun reading this too!
Happy hacking!